
| Version 8 (modified by , 3 months ago) ( diff ) |
|---|
GW16168 NXP Ara240 DNPU AI Accelerator
The GW16168 NXP Ara240 DNPU AI Accelerator is an M.2 2280 M-Key card by Gateworks for use in the Gateworks single board computers. For more product information see here: https://www.gateworks.com/products/gw16168-m2-ai-accelerator-usa-made/
Terminology
The following terminology is used in the Kinara documentation:
- Ara1 / Ara2 processor: An ultra low-power programmable Neural Network processor
- Kinara SDK: Kinara Software Development Kit
- DVNC: Kinara Network Compiler
- DVSim: Kinara Simulator
- DVConvert: Kinara Network Converter
- NNApp: Neural Network Application
- Development Platform: Machine to compile model and run simulator
- Target Platform: Platform which Ara1 / Ara2 processor connects to
- PPA: Power, Performance and Accuracy - metrics reported by the compiler
- SOF: Schedule Optimization Factor - a measure reported by the compiler
- CNN: Convolutional Neural Network - a deep learning model designed to analyze and process grid-like data such as images, videos and sometimes audio and text
- LLM: Large Language Model - an AI model trained on massive amounts of text data to understand, summarize, and generate human-like language
- VLM: Vision Language Model - a multimodal AI that bridges the gap between sight and language. It essentially gives an LLM the ability to "see" by integrating a vision encoder with a language
- sLLM: small Language Model - a lightweight version of an LLM designed to be more efficient, especially for "edge" devices with limited hardware resources
Documentation and links
Public:
- NXP ARA SDK Landing page
- https://github.com/nxp-imx/rt-sdk-ara2 - NXP's repo for ara2 runtime SDK v2.04 with dynamic linked binaries
- https://github.com/nxp-imx-support/uiodma-driver - Kernel driver GPL-2.0
NXP Ara240 DNPU AI Accelerator Quick Start
Using NXP deb distribution packages
Currently NXP is distributing the Ara2 runtime in binary form. They have released the kernel driver as opensource which resolves kernel compatibility issues which is a huge step but the userspace apps and libraries remain dynamic linked binary objects.
The current deb packages have some shortcomings:
- packages are not very consistent; some have a systemd service in the data, others create one via postinst
- they were intended to install on top of the NXP Embedded Linux Firmware (version L6.12.34-2.1.0) and intended to support only NXP dev kit boards so the dependencies are incomplete and don't match what would be on other Linux based root filesystems (Ubuntu system for example)
If you extract the deb's and examine the DEBIAN directory you can see how to install them on other boards and root filesystems.
It is fairly common for AI models to make use of python and NXP is using that here. The rt-sdk-ara2 includes a couple of Python Wheels that are used in the examples. A Python Wheel is a standard built-package format for distributing Python libraries. It is essentially a ZIP-format archive with a .whl extension that contains all the files needed for a package to run immediately after being. It's also standard when using Python to run into package version incompatibilities which is why user based Python virtual environments are used.
Note the deb files require an NXP account to download (from NXP ARA SDK Landing page) so the instructions below assume you have them already in the current directory.
rt-sdk-ara2
The ara2 runtime should not really be considered an 'SDK' - it has nothing to do with software development, its simply the set of utils and libs needed to use the Ara2.
The rt-sdk-ara2 provides a complete runtime environment for AI/ML acceleration using the Ara240 NPU on for aarch64. This package includes:
- Runtime libraries for Ara240 NPU integration
- Python bindings (DVAPI) for custom inference applications
- Optimum-Ara framework for LLMs and VLMs
- GStreamer plugins for Real-Time Detection Object Applications
- Helper scripts for monitoring, benchmarking, and model management
- Systemd service for automatic hardware initialization
Installation on a Gateworks board with Ubuntu based OS:
- extract the debian 'data' (do not install the package!)
# extract data (but don't install) dpkg-deb --vextract rt-sdk-ara2_2.0.4.deb / - take care of postinst steps
- miscelaneous
# create app dirs (used for models) mkdir -pv /usr/share/{cnn,llm} # get rid of circular symlink rm /usr/share/rt-sdk-ara240_2.0.4/rt-sdk-ara240_2.0.4
- install uv package manager for Python virtualization and packaging for local user (which is installed to ~/.local/bin so we create symlinks to /usr/bin)
apt update && apt install -y curl curl -LsSf https://astral.sh/uv/install.sh | sh ln -s /root/.local/bin/uv /usr/bin/uv ln -s /root/.local/bin/uvx /usr/bin/uvx
- build driver (the one in the deb is specific to the IMX BSP kernel)
apt update && apt install -y build-essential git bc file flex bison git clone https://github.com/nxp-imx-support/uiodma-driver ( cd uiodma-driver/uiodma; make ) # install it where the rt service expects to find it (over the top of the non-compatible one) cp uiodma-driver/uiodma/uiodma.ko /usr/share/rt-sdk-ara240/driver/
- enable service:
# enable service systemctl enable rt-sdk-ara2.service # start service now (unless you reboot) systemctl start rt-sdk-ara2.service
- use 'fetch_models' to pre-compiled models for testing via the fetch_models script which will fetch models from HuggingFace.
# list models available for nxp/ara fetch_models --list # install YOLOv8 fetch_models --repo-id nxp/YOLOv8 # 746MB (711MiB)
- the script is a python wrapper that uses uvx and the fetch-models python wheel (/usr/share/python-wheels/fetch_models-1.0.0-py3-none-any.whl) to fetch and install models from HuggingFace HUB
- the models will be installed in either /usr/share/cnn (Convolutional Neural Network) and /usr/share/llm (Large Language Model)
- NXP has Ara2 optimized models at https://huggingface.co/nxp
- the script has a hard coded list of models available and where to install them locally. You can use 'python -m zipfile -e /usr/share/python-wheels/fetch_models-1.0.0-py3-none-any.whl ./fetch_models' to see what it's doing
- miscelaneous
Notable Files:
- /usr/lib/
- libaraclient_aarch64.so - base library for interfacing with ara2
- libara_vision_inference.so - inference lib that builds on libaraclient
- /usr/lib/gstreamer-1.0
- libgstdvPre.so
- libgstdvInfo.so
- libgstdvPost.so
- /usr/share/rt-sdk-ara240 (symlink to a version independent dir at same location)
- hw_utils/boot_img - firmware files
- hw_utils/ddr_config - ddr binaries
- hw_utils/bins/ - the hw utils for bringup/programming
- optimum-ara/ - extension of the Hugging Face library that integrates with Ara240 DNPU
- scripts - various wrappers around the tools etc
- nnapp - tool for benchmarking models
- config - various example yaml config files used for proxy/nnapp
- include/dvapi.py - python bindings to dvapi
- driver/uiodma.ko - driver (where the setup script expects to find it)
- /usr/share/python-wheels - python wheels for fetch_models and optimum_ara
- /usr/shar/doc/rt-sdk-ara2 - license info
- /usr/include/sdk_ara - headers for C libs
- /usr/bin - various scripts
- /etc/udev/rules.d/99-ara2.rules - udev rule which makes the PCI ID dependent on the systemd service
- /etc/systemd/system/rt-sdk-ara2.service - systemd service that handles the various hw util config
- /etc/rt-sdk-ara240/cnn_config.yaml - config for nnapp
- /etc/rt-sdk-ara240/proxy_config.yam - config for proxy
Notes:
- This will not program flash - that is a manual step only required if there is an update
- The 'uv' package manager is a fast all-in-one Python package and project manager written in Rust which makes it easy to work with virtual env's to avoid Python package version clashing which is essential
- on bootup make sure you wait for the console messages indicating the Proxy is launched before using it as it can take a couple of minutes
- the binary tools and libs are all currently dynamic linked against stdlibc
- the GStreamer libs have compatibility issues with modern GStreamer
Verification steps:
- show chip_info
chip_info.sh
- verify service
# show service status systemctl status rt-sdk-ara2.service --no-pager -l # view detailed service logs journalctl -u rt-sdk-ara2.service # verify proxy is running (critical) ps -eaf | grep proxy_ara240
Examples:
- Download pre-compiled models for testing:
- The fetch_models script from the ara2-rt will fetch models from HuggingFace.
# list models available for nxp/ara fetch_models --list # install YOLOv8 fetch_models --repo-id nxp/YOLOv8 # 746MB (711MiB)
- the 'fetch_models' script is a python wrapper that uses uvx and the fetch-models python wheel (/usr/share/python-wheels/fetch_models-1.0.0-py3-none-any.whl) to fetch and install models from HuggingFace HUB
- the models will be installed in /usr/share/cnn (Convolutional Neural Network) and /usr/share/llm (Large Language Model)
- NXP has Ara2 optimized models at https://huggingface.co/nxp
- The fetch_models script from the ara2-rt will fetch models from HuggingFace.
- Run performance benchmark (uses nnapp)
run_model_perf.sh
- the 'run_model_perf.sh' script makes it easy to list and show model categories and models and is a wrapper around the nnapp app which has a lot of options and a config file
- monitor real-time NPU metrics including utilization, temperature, DRAM usage and device state (interactively during benchmarking or model execution)
ara2_metrics.sh
eIQ AAF Connector
The eIQ AAF Connector (edge Intelligence Ara Application Framework) is a REST-based server that enables LLM inference on NXP i.MX processors with the ARA-240 DNPU. The API implemented is the de-facto API standard created by OpenAI for ChatGPT. It provides a simple Chat Completions-based HTTP interface for serving models to client applications.
Requirements:
- python 3.13 (we will install in a virtual env)
- uv - used for the user-specific Python virtual environment
- Optimum Ara framework for running Large Language Models (LLMs) and Vision-Language Models (VLMs) on Ara240 (part of rt-sdk)
- OpenCV (dependency of the QwenVL engine)
- Models
Installation on a Gateworks board with Ubuntu based OS:
- extract the debian 'data' (do not install the package!)
# extract data (but don't install) dpkg-deb --vextract eiq-aaf-connector_2.0.deb / - take care of postinst steps
- Create the /usr/share/eiq/aaf-connector/venv (used by /usr/share/eiq/aaf-connector/venv/bin/connector)
# needs python 3.13 so we will install it in a virtual env for this user uv python install 3.13 uv venv --python 3.13 "/usr/share/eiq/aaf-connector/venv" # activate venv source "/usr/share/eiq/aaf-connector/venv/bin/activate" # install Python dependencies in venv from the Optimum Ara wheel uv pip install --no-progress /usr/share/python-wheels/optimum_ara-2.0.0.2-py3-none-any.whl # install Python dependencies in venv from the eIQ wheel in this package uv pip install --no-progress /usr/share/python-wheels/eiq_aaf_connector-2.0.0-py3-none-any.whl # ditch the default opencv-python which depends on libgl1-mesa and install the headless version instead uv pip uninstall opencv-python uv pip install opencv-python-headless # deactivate venv deactivate
- Create systemd service file (not sure why this wasn't in the deb)
cat > /etc/systemd/system/eiq-aaf-connector.service << EOF [Unit] Description=eIQ AAF Connector Service # No 'After' or 'Wants' for rt-sdk-ara2.service here # This prevents the 'Ordering Cycle' entirely After=network.target StartLimitIntervalSec=0 [Service] Type=simple User=root WorkingDirectory=/usr/share/eiq/aaf-connector # This loop now handles the dependency logic internally. # It will spin until the proxy is actually alive, regardless of # which service started it or when. ExecStartPre=/bin/bash -c 'until ss -Hltn | grep -E -q ":5000([[:space:]]|$)"; do echo "Waiting for ARA2 Proxy to initialize..." >&2; sleep 5; done' ExecStartPre=/bin/sleep 2 ExecStart=/usr/share/eiq/aaf-connector/venv/bin/connector --host 0.0.0.0 --port 8000 Restart=on-failure RestartSec=10s StartLimitBurst=0 StandardOutput=journal StandardError=journal [Install] WantedBy=multi-user.target EOF
- this one differs from the one in the deb's postinst script as I found that one to not work (it would not wait for the proxy to be alive)
- If you wish this to be accessible from the Network set the host to '0.0.0.0' instead of '127.0.0.1':
sed -i 's|--host 127.0.0.1|--host 0.0.0.0|g' /etc/systemd/system/eiq-aaf-connector.service
- add Ara2 optimized LLM models (these get installed to /usr/share/llm)
fetch_models --repo-id nxp/Qwen2.5-7B-Instruct-Ara240 # 7.7GiB fetch_models --repo-id nxp/Qwen2.5-Coder-1.5B-Ara240 # 1.67GiB
- edit the config file to enable the two models we just downloaded (using jq):
apt update && apt install -y jq jq '(.available_models[] | select(.name == "Qwen2.5-Coder-1.5B") | .enabled) = true' /usr/share/eiq/aaf-connector/server_config.json > /tmp/config.json && \ mv /tmp/config.json /usr/share/eiq/aaf-connector/server_config.json jq '(.available_models[] | select(.name == "Qwen2.5-7B-Instruct") | .enabled) = true' /usr/share/eiq/aaf-connector/server_config.json > /tmp/config.json && \ mv /tmp/config.json /usr/share/eiq/aaf-connector/server_config.json
- you can just as easily edit the file manually if you want
- Enable and start service
# Enable service on boot systemctl enable eiq-aaf-connector.service # Start the service now (or reboot) systemctl start eiq-aaf-connector.service
- Create the /usr/share/eiq/aaf-connector/venv (used by /usr/share/eiq/aaf-connector/venv/bin/connector)
Note that it takes several minutes for the service to actually be ready for connections as it must process the models (monitor with 'journalctl -u eiq-aaf-connector.service --no-pager -f' and test that its ready for listening with 'ss -tulpn | grep :8000').
By default, the connector configured above will start on 127.0.0.1:8000 which is the local loopback interface. To be able to run requests from another device, you can change the host to '0.0.0.0' in the service file.
Notable Files:
- /usr/share/eiq/aaf-connector/server_config.json (server config file)
- /usr/share/python-wheels/eiq_aaf_connector-2.0.0-py3-none-any.whl - Python wheel
- /usr/bin/aaf-connector - shell script that activates the venv and executes the connector
- /usr/share/eiq/aaf-connector/venv - Python virtual env used by connector
- /etc/systemd/system/eiq-aaf-connector.service - systemd service
The connector self-hosts API documentation at http://<serverip>:8000/docs
Example Usage:
- verify connector running
# show service status systemctl status eiq-aaf-connector.service --no-pager -l # view detailed service logs journalctl -u eiq-aaf-connector.service # verify process exists ps -ef | grep aaf-connector # verify port open ss -tulpn | grep :8000 # show IP:PORT server is listening on
- view API docs and interact with server (requires changing the host to '0.0.0.0' in the ExecStart config for /etc/systemd/system/eiq-aaf-connector.service by opening http://<serverip>:8000/docs
- use API via curl/jq
# make sure curl and jq are installed (jq allows easy interaction with json data) apt install -y curl jq # list of models curl -X 'GET' \ 'http://127.0.0.1:8000/v1/models' \ -H 'accept: application/json' | jq # get info about a specific model (Qwen2.5-7B-Instruct) curl -X 'GET' \ 'http://127.0.0.1:8000/params/Qwen2.5-7B-Instruct' \ -H 'accept: application/json' | jq # send a LLM query curl -X POST http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "Qwen2.5-7B-Instruct", "messages": [ {"role": "system", "content": "You are a helpful assistant running on NXP i.MX hardware."}, {"role": "user", "content": "Explain what an NPU is in one sentence."} ], "max_tokens": 50 }' | jq
- run connector by hand (useful for troubleshooting or monitoring)
systemctl stop eiq-aaf-connector.service source "/usr/share/eiq/aaf-connector/venv/bin/activate" connector --host 0.0.0.0 --port 8000 # will run until stopped deactivate
Ara2 SDK examples
Here are some Ara2 SDK examples that were 'vibe coded' within minutes
dvapi stats
This is an ANSI c app that provides an example of using the dvapi to connect to the proxy and obtain NPU endpoint stats such as temperature, clocks and usage. Basically it's a re-implementation of the closed source /usr/share/rt-sdk-ara240/scripts/ara2_metrics_bin/hw_metrics.out.
ara_status.c:
#include <stdio.h> #include <stdlib.h> #include "dvapi.h" int main() { dv_session_t *session = NULL; dv_endpoint_t *ep_list = NULL; int ep_count = 0; dv_status_code_t status; const char *socket_path = "/run/proxy.sock"; // 1. Establish session status = dv_session_create_via_unix_socket(socket_path, &session); if (status != DV_SUCCESS) { fprintf(stderr, "Failed to connect: %s\n", dv_stringify_status_code(status)); return 1; } // 2. Get list of NPU endpoints dv_endpoint_get_list(session, &ep_list, &ep_count); for (int i = 0; i < ep_count; i++) { dv_endpoint_t *ep = &ep_list[i]; dv_endpoint_statistics_t *stats = NULL; int s_count = 0; bool is_busy = false; // 3. Retrieve status and statistics dv_get_endpoint_busyness(session, ep, &is_busy); status = dv_endpoint_get_statistics(session, ep, &stats, &s_count); if (status == DV_SUCCESS && s_count > 0) { // DRAM Calculations (Bytes to GB) double used_gb = (double)stats->ep_dram_stats.ep_total_dram_occupancy_size / 1073741824.0; double total_gb = (double)stats->ep_dram_stats.ep_total_dram_size / 1073741824.0; double dram_pct = (total_gb > 0) ? (used_gb / total_gb) * 100.0 : 0.0; // NPU Utilization (Queue occupancy) double npu_load = 0.0; if (stats->ep_infq_stats && stats->ep_infq_stats->length > 0) { npu_load = ((double)stats->ep_infq_stats->occupancy_count / stats->ep_infq_stats->length) * 100.0; } printf("--- NPU Endpoint %d Statistics ---\n", i); printf("Busy State: %s\n", is_busy ? "TRUE" : "FALSE"); printf("NPU Utilization: %.1f%%\n", npu_load); printf("Temperature: %.1f C\n", stats->ep_temp); printf("NNP Clock: %d MHz\n", stats->ep_nnp_clk); printf("SBP Clock: %d MHz\n", stats->ep_sbp_clk); printf("DRAM Clock: %d MHz\n", stats->ep_dram_clk); // Format: DRAM Usage: 8.2GB/16.0GB (51.3%) printf("DRAM Usage: %.1fGB/%.1fGB (%.1f%%)\n", used_gb, total_gb, dram_pct); printf("\n"); dv_endpoint_free_statistics(stats, s_count); } } // 4. Cleanup dv_endpoint_free_group(ep_list); dv_session_close(session); return 0; }
Compile:
apt update && apt install build-essentials
gcc ara_status.c -I/usr/include/sdk_ara/ -L/usr/lib/ -laraclient_aarch64 -o ara_status
Execution:
# ./ara_status --- NPU Endpoint 0 Statistics --- Busy State: FALSE NPU Utilization: 0.0% Temperature: 56.0 C NNP Clock: 900 MHz SBP Clock: 355 MHz DRAM Clock: 1066 MHz DRAM Usage: 10.0GB/16.0GB (62.5%)
command-line python eIQ chatbot
This is a command-line chatbot written in python using the eIQ AAF Connector
chat.py:
import json import requests import time import sys API_URL = "http://127.0.0.1:8000/v1/chat/completions" MODEL_NAME = "Qwen2.5-7B-Instruct" def chat(): print(f"--- i.MX LLM Session (Model: {MODEL_NAME}) ---") print("Type 'exit' to stop.\n") history = [{"role": "system", "content": "You are a helpful AI assistant."}] while True: user_input = input("You: ") if user_input.lower() in ['exit', 'quit']: break history.append({"role": "user", "content": user_input}) payload = { "model": MODEL_NAME, "messages": history, "temperature": 0.7, "stream": True } print("AI: ", end="", flush=True) # Start timing start_time = time.time() full_reply = "" token_count = 0 try: response = requests.post(API_URL, json=payload, stream=True) response.raise_for_status() for line in response.iter_lines(): if line: decoded_line = line.decode('utf-8') if decoded_line.startswith("data: "): content = decoded_line[6:] if content.strip() == "[DONE]": break chunk = json.loads(content) if "choices" in chunk and chunk["choices"][0]["delta"].get("content"): text = chunk["choices"][0]["delta"]["content"] print(text, end="", flush=True) full_reply += text token_count += 1 # Rough estimate of tokens # End timing end_time = time.time() duration = end_time - start_time tps = token_count / duration if duration > 0 else 0 print(f"\n\n--- Stats ---") print(f"Time taken: {duration:.2f} seconds") print(f"Throughput: {tps:.2f} tokens/sec") print(f"-------------\n") history.append({"role": "assistant", "content": full_reply}) except Exception as e: print(f"\nError: {e}") if __name__ == "__main__": chat()
Execution:
$ uv venv # create virtual python env in current dir $ uv pip install requests # install python deps $ uv run chat.py # run in venv --- i.MX LLM Session (Model: Qwen2.5-7B-Instruct) --- Type 'exit' to stop. You: Why is the sky blue AI: The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight enters the Earth's atmosphere, it collides with molecules and small particles in the air. Sunlight is made up of different colors, each of which has a different wavelength. Blue light has a shorter wavelength and is scattered more than other colors by the gases and particles in the atmosphere. This scattering makes the sky appear blue to our eyes. During sunrise and sunset, the sky can appear red or orange because the light has to travel through more of the Earth's atmosphere. This longer path means that more blue and green light is scattered out of the beam, leaving the red and orange wavelengths to dominate the light that reaches our eyes. So, the blue color of the sky is primarily due to the way shorter wavelength light is scattered by the Earth's atmosphere. --- Stats --- Time taken: 29.18 seconds Throughput: 5.04 tokens/sec ------------- You: exit
Web based python eIQ chatbot
This is a web based chatbot in python using eIQ AAF Connector
webchat.py:
import sys import os from datetime import datetime # --- KINARA SDK PATH INJECTION --- DVAPI_DIR = "/usr/share/rt-sdk-ara240_2.0.4/include" if os.path.exists(DVAPI_DIR): sys.path.append(DVAPI_DIR) import streamlit as st import requests import json import time import psutil import threading import argparse # Attempt to import the Kinara Python APIs try: from dvapi import DVSession, dv_endpoint_get_statistics, dv_endpoint_free_statistics except ImportError: st.error(f"Critical: dvapi.py not found at {DVAPI_DIR}") st.stop() # --- ARGUMENT PARSING --- parser = argparse.ArgumentParser() parser.add_argument("--host", type=str, default="127.0.0.1", help="AAF Connector Host") parser.add_argument("--port", type=str, default="8000", help="AAF Connector Port") parser.add_argument("--proxy-sock", type=str, default="/var/run/proxy.sock", help="Kinara Proxy socket") args, _ = parser.parse_known_args() # --- CONFIGURATION --- MODEL_NAME = "Qwen2.5-7B-Instruct" API_URL = f"http://{args.host}:{args.port}/v1/chat/completions" LOGO_URL = "/root/gateworks_logo.png" # --- HARDWARE TELEMETRY HELPERS --- def get_dvapi_npu_stats(): try: ret, session = DVSession.create_via_unix_socket(args.proxy_sock) if ret != 0: return None with session: ret, ep_list = session.get_endpoint_list() if ret != 0 or not ep_list: return None ret, stats_ptr, count = dv_endpoint_get_statistics(session._session, ep_list[0]._endpoint) if ret == 0 and count.value > 0: s = stats_ptr[0] TOTAL_CAPACITY_GB = 16.0 free_gb = s.ep_dram_stats.ep_total_free_size / 1073741824 used_gb = max(0, TOTAL_CAPACITY_GB - free_gb) dram_pct = (used_gb / TOTAL_CAPACITY_GB) * 100 is_busy = st._npu_lock.locked() data = {"temp": s.ep_temp, "util": 100 if is_busy else 0, "ram_pct": dram_pct} dv_endpoint_free_statistics(stats_ptr, count) return data except: return None def get_system_thermals(): zones = [] try: for zone in sorted(os.listdir("/sys/class/thermal/")): if zone.startswith("thermal_zone"): with open(f"/sys/class/thermal/{zone}/temp", "r") as f: z_temp = int(f.read().strip()) / 1000.0 zones.append(z_temp) except: pass return zones def build_sidebar_html(): n_stats = get_dvapi_npu_stats() cpu_usage = psutil.cpu_percent() sys_ram = psutil.virtual_memory().percent thermals = get_system_thermals() npu_html = f"<div style='border-top:1px solid #444; padding-top:5px; font-size:0.82rem;'><b>🔥 Ara2 NPU</b><br>" if n_stats: npu_html += f"NPU: {n_stats['util']}% {n_stats['temp']:.1f}C | RAM: {n_stats['ram_pct']:.1f}%" else: npu_html += "NPU Telemetry Unavailable" npu_html += "</div>" sys_html = f"<div style='border-top:1px solid #444; margin-top:8px; padding-top:5px; font-size:0.82rem;'><b>💻 Syst m</b><br>" temp_str = "/".join([f"{t:.1f}C" for t in thermals]) sys_html += f"CPU: {cpu_usage:.1f}% {temp_str} | RAM: {sys_ram:.1f}%</div>" perf_val = st.session_state.get('last_perf', 'N/A') perf_html = f"<div style='border-top:1px solid #444; margin-top:8px; padding-top:5px; font-size:0.82rem;'><b>⚡ Las Result</b><br>{perf_val}</div>" return npu_html + sys_html + perf_html # --- GLOBAL STATE --- if not hasattr(st, '_npu_lock'): st._npu_lock = threading.Lock() if not hasattr(st, '_active_user'): st._active_user = "None" st.set_page_config(page_title="Gateworks Venice AI", layout="wide") # --- SIDEBAR --- with st.sidebar: try: st.image(LOGO_URL, width=220) except: st.write("### Gateworks Venice") status_slot = st.empty() # Simplified to just show the IP address user_id = st.context.ip_address or "127.0.0.1" if st._npu_lock.locked(): status_slot.warning(f"⚠️ BUSY: {st._active_user}") else: status_slot.success("🟢 READY") st.caption(f"User: {user_id}") stats_slot = st.empty() stats_slot.markdown(build_sidebar_html(), unsafe_allow_html=True) # --- MAIN INTERFACE --- st.title("🤖 i.MX Edge LLM") if "messages" not in st.session_state: st.session_state.messages = [] for msg in st.session_state.messages: with st.chat_message(msg["role"]): st.markdown(msg["content"]) if prompt := st.chat_input("Ask the NPU..."): st.chat_message("user").markdown(prompt) st.session_state.messages.append({"role": "user", "content": prompt}) # Console: Log the Incoming Request / Queue status ts_in = datetime.now().strftime("%H:%M:%S") print(f"[{ts_in}] QUEUED: Request from {user_id} -> '{prompt[:40]}...'") with st.chat_message("assistant"): response_placeholder = st.empty() # This lock handles the "Queued" logic—it will block here if someone else is talking with st._npu_lock: st._active_user = user_id status_slot.warning(f"⚠️ BUSY: {user_id}") ts_start = datetime.now().strftime("%H:%M:%S") print(f"[{ts_start}] PROCESSING: Active inference for {user_id}") full_response, token_count, start_time = "", 0, time.time() try: payload = {"model": MODEL_NAME, "messages": st.session_state.messages, "stream": True} r = requests.post(API_URL, json=payload, stream=True, timeout=120) for line in r.iter_lines(): if line: decoded = line.decode('utf-8').replace('data: ', '') if decoded.strip() == "[DONE]": break try: chunk = json.loads(decoded) content = chunk["choices"][0]["delta"].get("content", "") if content: full_response += content token_count += 1 response_placeholder.markdown(full_response + "▌") if token_count % 12 == 0: stats_slot.markdown(build_sidebar_html(), unsafe_allow_html=True) except: continue duration = time.time() - start_time tps = token_count / duration if duration > 0 else 0 st.session_state.last_perf = f"{token_count} tokens @ {tps:.1f} t/s" response_placeholder.markdown(full_response) st.session_state.messages.append({"role": "assistant", "content": full_response}) # Console: Log Completion ts_out = datetime.now().strftime("%H:%M:%S") print(f"[{ts_out}] COMPLETE: {user_id} | {token_count} tokens | {tps:.1f} t/s") except Exception as e: st.error(f"Error: {e}") print(f"[{datetime.now().strftime('%H:%M:%S')}] ERROR: {e}") finally: st._active_user = "None" stats_slot.markdown(build_sidebar_html(), unsafe_allow_html=True) status_slot.success("🟢 READY") st.rerun()
Execution:
$ mkdir /root/webapp $ cd /root/webapp $ uv venv # create virtual python env in current dir $ uv pip install streamlit requests psutil argparse # install python deps $ uv run streamlit run webchat.py --server.address 0.0.0.0 --server.port 8501 -- --user-map users.json --host 127.0.0.1 --port 8000
Service:
- if want this to run as a service:
cat << EOF > /etc/systemd/system/eiq-webapp.service: [Unit] Description=Streamlit Webapp for eIQ AAF # Start after network is up After=network.target # We don't use 'After=eiq-aaf-connector.service' to avoid potential boot cycles StartLimitIntervalSec=0 [Service] Type=simple User=root # Ensure we are in the directory where webapp.py lives WorkingDirectory=/root/webapp # 1. Wait until the Connector is actually listening on Port 8000 ExecStartPre=/bin/bash -c 'until ss -Hltn | grep -E -q ":8000([[:space:]]|$)"; do echo "Waiting for eIQ Connector on Port 8000..." >&2; sleep 5; done' # 2. Launch the app using uv # Note: Using absolute path for uv is safer in systemd ExecStart=/usr/local/bin/uv run streamlit run webapp.py \ --server.address 0.0.0.0 \ --server.port 8501 \ -- \ --user-map users.json \ --host 127.0.0.1 \ --port 8000 # Restart logic Restart=on-failure RestartSec=10s StartLimitBurst=0 # Standard Logging StandardOutput=journal StandardError=journal [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable eiq-webapp.service systemctl start eiq-webapp.service
Troubleshooting
Please note software support should be routed through NXP, who produces the Ara240 DNPU Chip.
Attachments (11)
-
dog.jpg
(163.2 KB
) - added by 6 weeks ago.
COCO validation image with a dog on a bench
-
dog_detect.jpg
(166.6 KB
) - added by 6 weeks ago.
COCO dog image with detections
-
traffic_detect_yolo8n.jpg
(600.4 KB
) - added by 6 weeks ago.
Traffic image with detections via yolo8n
-
traffic_detect_yolo8x.jpg
(619.0 KB
) - added by 6 weeks ago.
Traffic image with detections via yolo8x
-
image_detect.py
(6.6 KB
) - added by 6 weeks ago.
image detection command line app
-
vision-webapp.py
(19.2 KB
) - added by 6 weeks ago.
video inference webapp
-
vision-webapp.png
(509.7 KB
) - added by 6 weeks ago.
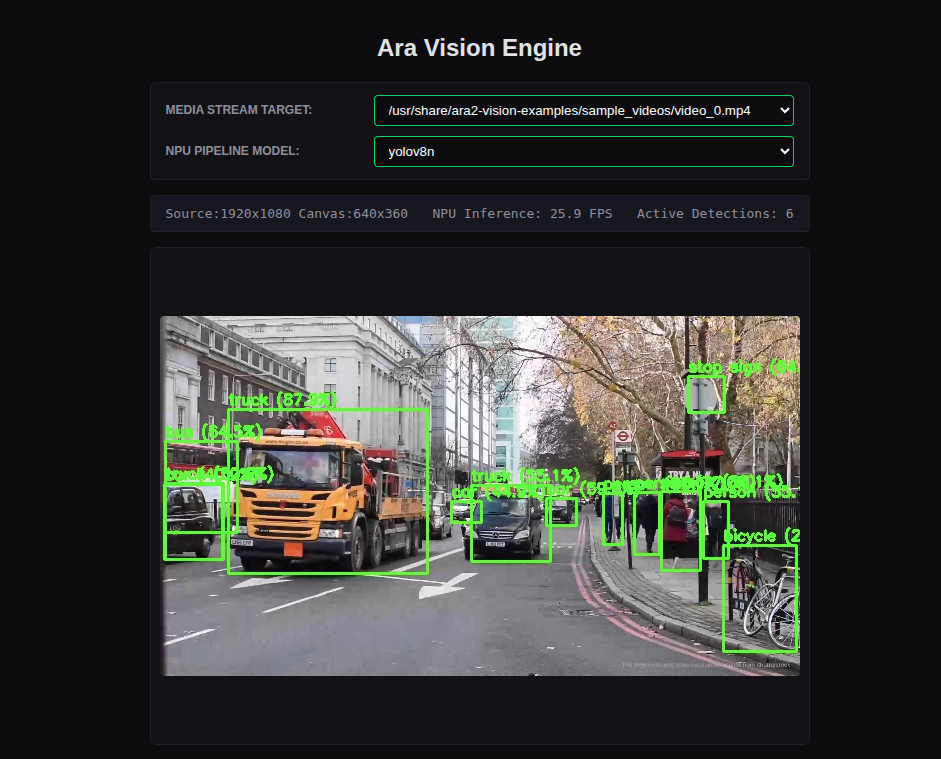
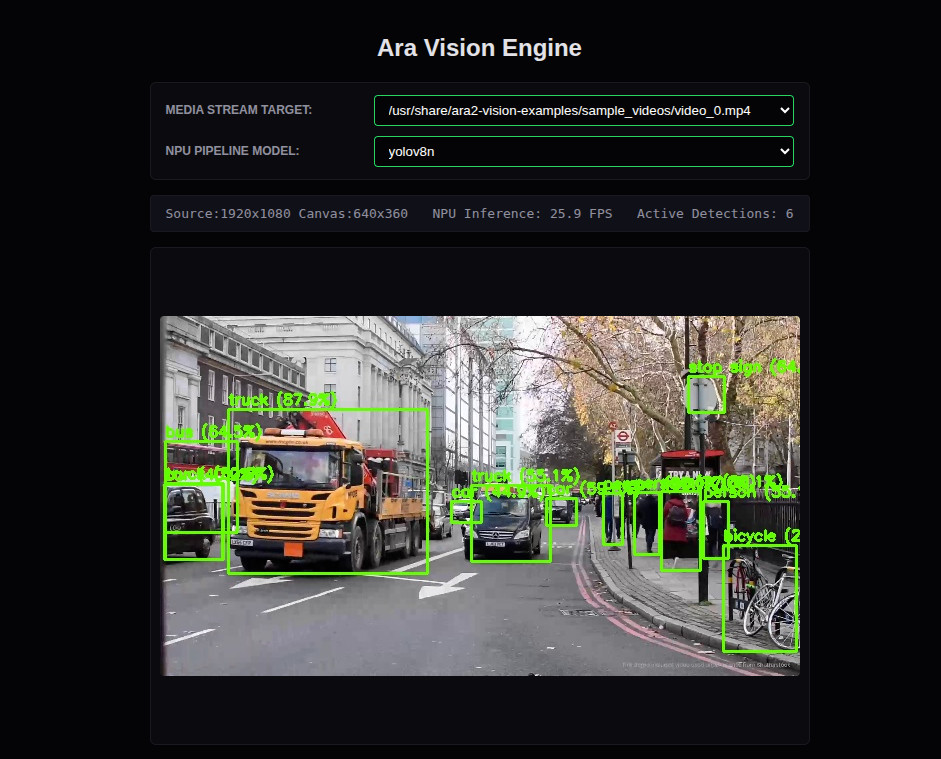
screenshot of vision webapp performing labelling on an mp4 of traffic
-
vlm-webapp.png
(414.8 KB
) - added by 6 weeks ago.
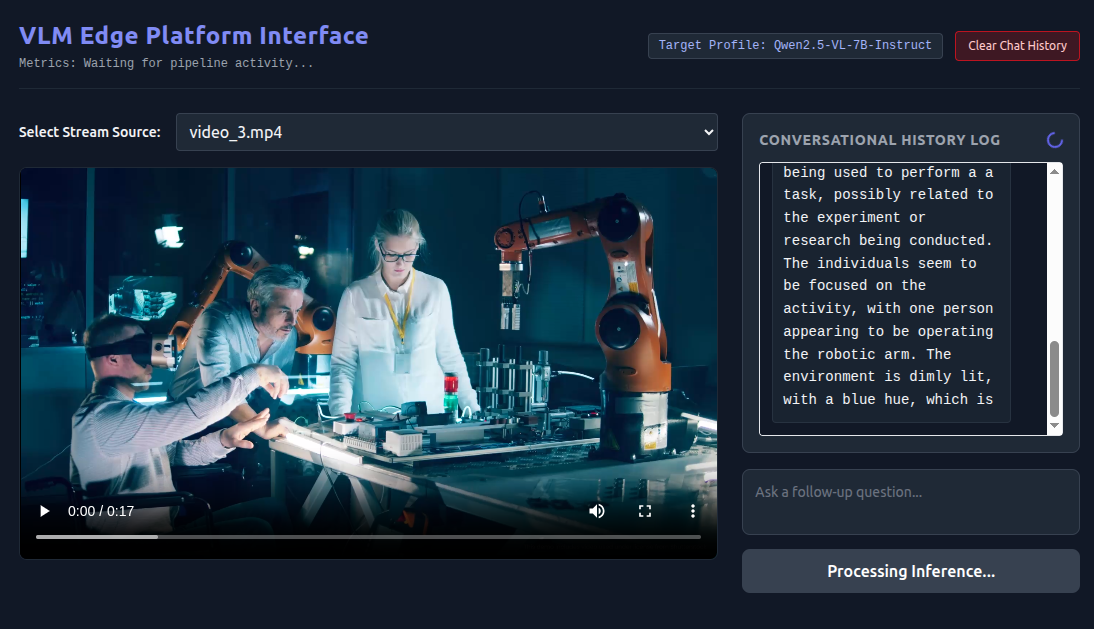
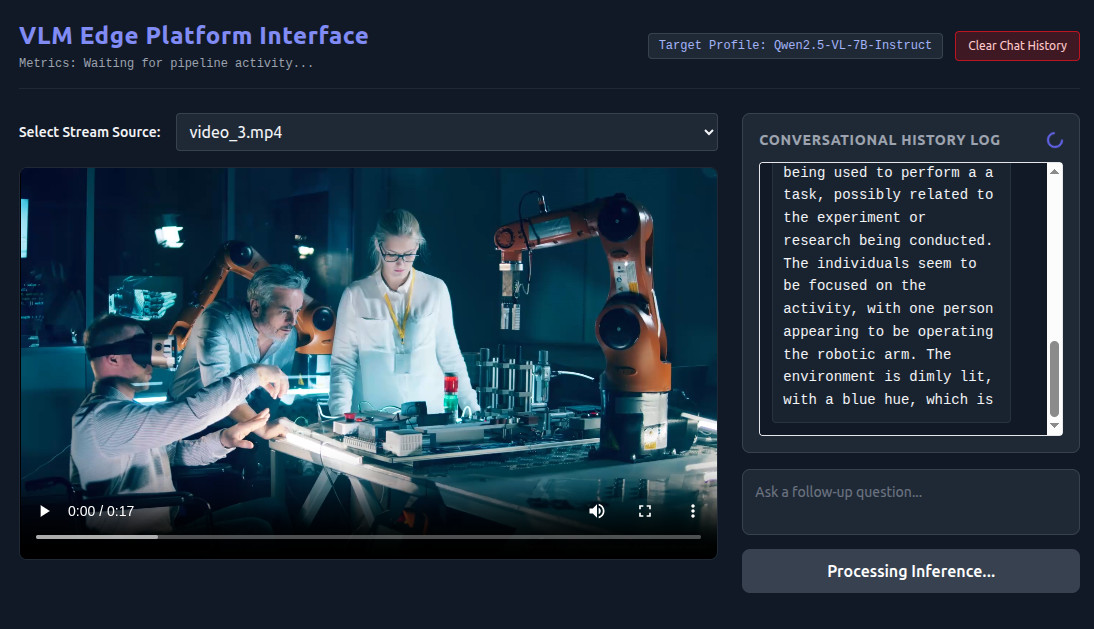
screenshot of vlm webapp showing processing of what is going on in a video
-
traffic.jpg
(560.5 KB
) - added by 6 weeks ago.
Traffic image
-
vision-webapp.jpg
(169.4 KB
) - added by 6 weeks ago.
screenshot of vision webapp performing labelling on an mp4 of traffic
-
vlm-webapp.jpg
(176.0 KB
) - added by 6 weeks ago.
screenshot of vlm webapp showing processing of what is going on in a video
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip