
-
IMX8MP Neural Processing Unit
- Upstream / Mainline NPU support (via Mesa)
- Other AI Chipsets and Solutions
-
NXP Yocto BSP
- 1. Download the Gateworks Venice Rescue Image to removable multimedia.
- 2. Download the NXP BSP evaluation kit image to removable multimedia.
- 3. Patch & Build patch Venice DTBs from the Kernel source.
- 4. Boot Rescue Image ramdisk on board
- Flash NXP .wic and patched DTBs onto eMMC
- Boot into the NXP image.
- Image Classification Example
- GStreamer Example for Detection
- References
IMX8MP Neural Processing Unit
The Gateworks Venice SBCs that are using the i.MX8M Plus processors have a built in Neural Processing Unit (NPU) for machine learning.
- All GW74xx use the i.MX8M Plus processor
- Any GW71xx, GW72xx and GW73xx using a GW702x SOM module will use the i.MX8M Plus processor
Please note other AI accelerators can also be added via expansion slots described here
The IMX8MP NPU IP is VeriSilicon (Vivante VIP8000) and offers 2.3 TOPS of acceleration for inference in endpoint devices; object identification, speech recognition of 40K words, or even medical imaging (MobileNet v1 at 500 images per second). Out of the box, this makes Gateworks boards with NPU capabilities powerful for AI applications on the edge.

Upstream / Mainline NPU support (via Mesa)
The IMX8MP has a Verisilicon NPU which is from Vivante. Vivante supports this via their vivante driver (/dev/galcore) but that is not an opensource driver so it would make sense to want to support the NPU with it's opensource equivalent (etnaviv driver). Support for this has been added to the Linux 6.10 kernel.
The Mesa project began as an open-source userspace library implementation of the OpenGL specification - a system for rendering interactive 3D graphics. Over the years the project has grown to implement more graphics APIs, including OpenGL ES, OpenCL, VDPAU, VA-API, Vulkan and EGL. Mesa now supports NPUs as well as they are closely tied to GPUs.
Support has been merged into Mesa for the IMX8MP NPU via the teflon delegate thanks to Tomeu Vizoso and Ideas On board who sponsored the work. The specific code merges are 1 and 2) which are expected to land in the 25.0 release.
Until this version of Mesa is packaged for your OS distribution you will need to build the Mesa library manually.
Requirements:
- Gateworks Venice board with an IMX8MP and an Ubuntu noble root filesystem with a 6.10 or newer kernel
- Create a non-root user (always a good idea but not required for mesa)
# create user USER=gateworks useradd -s /bin/bash $USER mkdir /home/$USER; chown $USER /home/$USER # allow sudo for this user echo "$USER ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers # add render group (needed for some examples) usermod -aG render $USER # login as this user su -l $USER
- To avoid a lot of python dependency issues with tensorflow-lite install an older version of python using the deadsnakes ppa and create a virtualenv
sudo add-apt-repository ppa:deadsnakes/ppa sudo apt update sudo apt install -y python3.9 python3.9-venv # create tflite-env virtualenv python3.9 -m venv tflite-env # activate the venv (repeat or every new shell) source tflite-env/bin/activate
- Note Python 3.9, 3.10, 3.11 work, 3.12 does not
- Build mesa (22.2.0-devel fork with updated teflon support for imx8mp)
# install build deps sudo apt install -y build-essential git cmake sudo apt-get -y build-dep mesa # get repo git clone https://gitlab.freedesktop.org/tomeu/mesa.git -b etnaviv-imx8mp mesa cd mesa # mesa requires meson (v1.1.0 or greater), pycparser (2.20 or greater), and mako pip3 install meson pycparser mako sudo apt-get install -y libxfixes-dev libxext-dev libudev-dev libx11-xcb-dev libxcb-glx0-dev libxcb-shm0-dev meson setup build -Dgallium-drivers=etnaviv -Dvulkan-drivers= -Dteflon=true meson compile -C build # 20 mins or so on imx8mp ldd build/src/gallium/targets/teflon/libteflon.so cd ..
- Install tensorflow lite runtime (requires python <= 2.11)
pip3 install tflite_runtime
- Clone tensorflow for some examples and assets used below
git clone https://github.com/tensorflow/tensorflow.git
- Run teflon image classification test
# Note this test requires python pillow, python numpy<2.0 and write access to /dev/dri/renderD128 pip3 install "numpy<2.0" pillow groups # make sure your in the render group (or have write access to /dev/dri/renderD128) # without teflon (175.335ms on imx8mp) python3 ~/mesa/src/gallium/frontends/teflon/tests/classification.py \ -i ~/tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp \ -m ~/mesa/src/gallium/targets/teflon/tests/mobilenet_v1_1.0_224_quant.tflite \ -l ~/mesa/src/gallium/frontends/teflon/tests/labels_mobilenet_quant_v1_224.txt # with teflon (7.651ms on imx8mp) python3 ~/mesa/src/gallium/frontends/teflon/tests/classification.py \ -i ~/tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp \ -m ~/mesa/src/gallium/targets/teflon/tests/mobilenet_v1_1.0_224_quant.tflite \ -l ~/mesa/src/gallium/frontends/teflon/tests/labels_mobilenet_quant_v1_224.txt \ -e ~/mesa/build/src/gallium/targets/teflon/libteflon.so
- Run tensorflow label_image example:
- First we need to patch the label_image example to use tflite_runtime. Use a text editor like vi to edit the file ~/tensorflow/tensorflow/lite/examples/python/label_image.py per the patch changes below:
diff --git a/tensorflow/lite/examples/python/label_image.py b/tensorflow/lite/examples/python/label_image.py index d26454f921f..08c65962bf1 100644 --- a/tensorflow/lite/examples/python/label_image.py +++ b/tensorflow/lite/examples/python/label_image.py @@ -19,7 +19,7 @@ import time import numpy as np from PIL import Image -import tensorflow as tf +import tflite_runtime.interpreter as tflite def load_labels(filename): @@ -85,7 +85,7 @@ if __name__ == '__main__': tflite.load_delegate(args.ext_delegate, ext_delegate_options) ] - interpreter = tf.lite.Interpreter( + interpreter = tflite.Interpreter( model_path=args.model_file, experimental_delegates=ext_delegate, num_threads=args.num_threads)
- Now we can run the label_image example:
# without acceleration (175.993ms on imx8mp) python3 ~/tensorflow/tensorflow/lite/examples/python/label_image.py \ -m ~/mesa/src/gallium/targets/teflon/tests/mobilenet_v1_1.0_224_quant.tflite \ -l ~/mesa/src/gallium/frontends/teflon/tests/labels_mobilenet_quant_v1_224.txt \ -i ~/tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp 0.874510: military uniform 0.031373: Windsor tie 0.015686: mortarboard 0.011765: bulletproof vest 0.007843: bow tie time: 176.267ms # with acceleration (14.138ms on imx8mp) python3 ~/tensorflow/tensorflow/lite/examples/python/label_image.py \ -m ~/mesa/src/gallium/targets/teflon/tests/mobilenet_v1_1.0_224_quant.tflite \ -l ~/mesa/src/gallium/frontends/teflon/tests/labels_mobilenet_quant_v1_224.txt \ -i ~/tensorflow/tensorflow/lite/examples/label_image/testdata/grace_hopper.bmp \ -e ~/mesa/build/src/gallium/targets/teflon/libteflon.so Loading external delegate from /root/mesa/build/src/gallium/targets/teflon/libteflon.so with args: {} 0.870588: military uniform 0.031373: Windsor tie 0.011765: mortarboard 0.007843: bow tie 0.007843: bulletproof vest time: 14.234ms
- First we need to patch the label_image example to use tflite_runtime. Use a text editor like vi to edit the file ~/tensorflow/tensorflow/lite/examples/python/label_image.py per the patch changes below:
Other AI Chipsets and Solutions
Please note other AI accelerators can also be added via expansion slots described here
NXP Yocto BSP
Another option to explore the NPU is to use an image from the NXP BSP.
NOTE Gateworks typically uses a mainline kernel and Ubuntu, etc. If using the NXP image, it is a completely different eco-system that will require a lot of learning, etc. It may be handy to explore the NPU, but for a larger project, the mainline MESA option above may be better.
This NXP image contains the necessary libraries and kernel to interface the NPU with TensorFlow without much configuration. You can either follow the guide to build their image or download a pre-built one (recommended).
This guide assumes you have:
- A Gateworks board with a i.MX8M Plus procesor.
- A NXP account, which is necessary to download their image and models.
- A >= 16GB flash drive, SD card, or other removable block storage to install a Rescue Image, NXP Image, and updated device trees (DTBs) onto the board.
The steps are as generalized as possible to not depend on the boards available RAM to load an image, or the low speeds of JTAG uploading, as the .wic from NXP is >8GB. We will use a ramdisk to boot a "rescue image" fully in RAM, then use dd to write from the removable multimedia (flash drive) to the onboard eMMC (/dev/mmcblk2).
NOTE: In the scripts below, we disable PCIe as a temporary fix to prevent the NXP 6.6.3_1.0.0 kernel from hanging on boot. This is caused by a missing patch necessary to work around a PCIe switch quirk when used on the IMX8MP, which can be found specifically here from our kernel.
1. Download the Gateworks Venice Rescue Image to removable multimedia.
Find which device your flash drive/SD card is. For example, /dev/sdc
Then, use dd to flash this image onto your device byte-for-byte.
DEVICE=<your device, no trailing /> wget https://dev.gateworks.com/buildroot/venice/minimal/rescue.img.gz zcat rescue.img.gz | sudo dd of=${DEVICE} bs=1M oflag=sync
In this guide, we will have the NXP image and our rescue image on the same drive, so we will resize the partition and file system to fit both. If you're using separate devices, this is not necessary.
sudo parted ${DEVICE} "resizepart 1 -0" # resize the partition to fit the size of the drive sudo resize2fs ${DEVICE}1 # resize ext fs on device partition 1
2. Download the NXP BSP evaluation kit image to removable multimedia.
On your host machine, install the Linux 6.6.3_1.0.0 image for the i.MX 8M Plus EVK here.
In this download you will find imx-image-full-imx8mpevk.wic, which is a Yocto-generated image with all of the ML libraries. Copy this image to our device.
sudo mount ${DEVICE}1 /mnt sudo cp imx-image-full-imx8mpevk.wic /mnt/
3. Patch & Build patch Venice DTBs from the Kernel source.
Due to small inconsistencies between the NXP and Gateworks devicetrees for bleeding-edge peripherals, a patch is required until mainline compatibility is reached. The below script gets the patches from the attachments at the bottom of this page.
git clone https://github.com/nxp-imx/linux-imx -b lf-6.6.y cd linux-imx wget https://trac.gateworks.com/raw-attachment/wiki/venice/npu/0001-arm64-dts-imx8mp-venice-fix-USB_OC-pinmux.patch wget https://trac.gateworks.com/raw-attachment/wiki/venice/npu/0002-arm64-dts-imx8mm-venice-gw700x-remove-ddrc.patch wget https://trac.gateworks.com/raw-attachment/wiki/venice/npu/0003-arm64-dts-freescale-add-Gateworks-venice-board-dtbs.patch wget https://trac.gateworks.com/raw-attachment/wiki/venice/npu/0004-arm64-dts-imx8mp-venice-gw74xx-enable-gpu-nodes.patch patch -p1 < 0001-arm64-dts-imx8mp-venice-fix-USB_OC-pinmux.patch patch -p1 < 0002-arm64-dts-imx8mm-venice-gw700x-remove-ddrc.patch patch -p1 < 0003-arm64-dts-freescale-add-Gateworks-venice-board-dtbs.patch patch -p1 < 0004-arm64-dts-imx8mp-venice-gw74xx-enable-gpu-nodes.patch ARCH=arm64 make imx_v8_defconfig ARCH=arm64 make dtbs
Copy these patched dtbs to a directory on your flash such as /nxp/, as to not overwrite the ones necessary for booting into the rescue image.
sudo mkdir /mnt/nxp sudo cp arch/arm64/boot/dts/freescale/*venice*.dtb /mnt/nxp/
Now, the contents of the device should include:
- Rescue image
- Rescue image dtbs
- rootfs.cpio.xz and boot.scr for booting Rescue Image
- nxp/ with new, updated dtbs
4. Boot Rescue Image ramdisk on board
Connect the removable multimedia, in our case a USB stick, to the board before powering. Many boards have built-in SD readers, which would change the device commands slightly.
Connect serial console via JTAG and power on the board. Enter the U-Boot console by stopping autoboot.
Sanity check: is the USB device properly detected?
usb start
part list usb 0
This command should have an expected output like below
Partition Map for USB device 0 -- Partition Type: DOS Part Start Sector Num Sectors UUID Type 1 2048 204800 6fd772a2-01 83 Boot
Override the boot_targets variable temporarily to ensure booting into the Rescue Image, then boot into it. If you are not using usb0, run print boot_targets to see a list.
setenv boot_targets usb0 run bootcmd
If all functions normally, you should be met with a login; login with root and you will enter the shell.
Flash NXP .wic and patched DTBs onto eMMC
You are now booted into the ramdisk rescue image. The next steps are to flash the .wic onto the emmc.
For venice boards the emmc that we are imaging is /dev/mmcblk2 and with only one removable storage device your rescue image with be /dev/sda.
Image the emmc as followes:
mkdir /mnt/src mkdir /mnt/dst mount /dev/sda1 /mnt/src dd if=/mnt/src/imx-image-full-imx8mpevk.wic of=/dev/mmcblk2 bs=16M oflag=sync # this will take a couple of minutes mount /dev/mmcblk2p1 /mnt/dst cp /mnt/src/*.dtb /mnt/dst/ cp /mnt/src/nxp/*.dtb /mnt/dst/
This flashes the prebuilt .wic image (both partitions, the kernel and fs) to our eMMC, then also brings over the old and new device trees. Next, we will create the boot script. If the below doesn't copy right, the file can be created/edited in a text editor like vi; just remove the EOF line.
cat <<\EOF > boot.scr.txt setenv bootargs 'root=/dev/mmcblk2p2' load mmc 2:1 $kernel_addr_r Image setenv fdt_addr setenv fdt_list $fdt_file $fdt_file1 $fdt_file2 $fdt_file3 $fdt_file4 $fdt_file5 setenv load_fdt 'echo Loading $fdt...; load ${devtype} ${devnum}:${distro_bootpart} ${fdt_addr_r} ${prefix}${fdt} && setenv fdt_addr ${fdt_addr_r}' for fdt in ${fdt_list}; do if test -e ${devtype} ${devnum}:${distro_bootpart} ${prefix}${fdt}; then run load_fdt; fi; done if test -z "$fdt_addr"; then echo "Warning: Using bootloader DTB"; setenv fdt_addr $fdtcontroladdr; fi #Disables PCI; patch is needed, otherwise kernel hangs: See note at start of wiki page. fdt addr $fdt_addr_r && fdt resize && fdt set /soc@0/pcie@33800000 status disabled booti $kernel_addr_r - $fdt_addr_r EOF
'Compile' the boot script txt and flash it onto the MMC
mkimage -A arm64 -T script -C none -d boot.scr.txt /mnt/dst/boot.scr umount /mnt/dst umount /mnt/src
Boot into the NXP image.
Power cycle the board, and note the kernel which it boots into. The board should automatically boot into the eMMC image we just flashed, meaning the removable multimedia need not be connected.
If there is an error, look at the logs and the boot scripts in U-Boot.
At this point, all features regarding the Kernel and below are properly enabled. If you have an application that uses TensorFlow, it will run on the NPU or GPU using /usr/lib/libvx_delegate.so. Follow the NXP Machine Learning User's Guide for more information.
Image Classification Example
As per the NXP Machine Learning User's Guide, we will test a simple image labeling script on both the CPU and NPU.
$ cd /usr/bin/tensorflow-lite-2.15.0/examples $ python3 label_image.py # without NPU acceleration $ python3 label_image.py -e /usr/lib/libvx_delegate.so # with NPU accerlation via the libvx_delegate external TensorFlow delegate
Result from either label_image script:
0.878431: military uniform 0.027451: Windsor tie 0.011765: mortarboard 0.011765: bulletproof vest 0.007843: sax
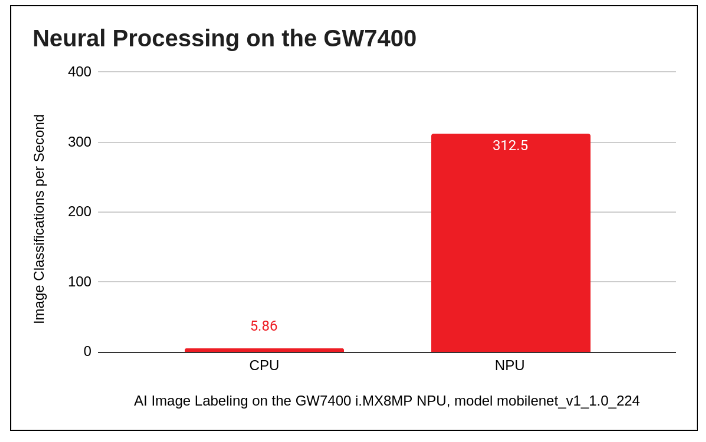
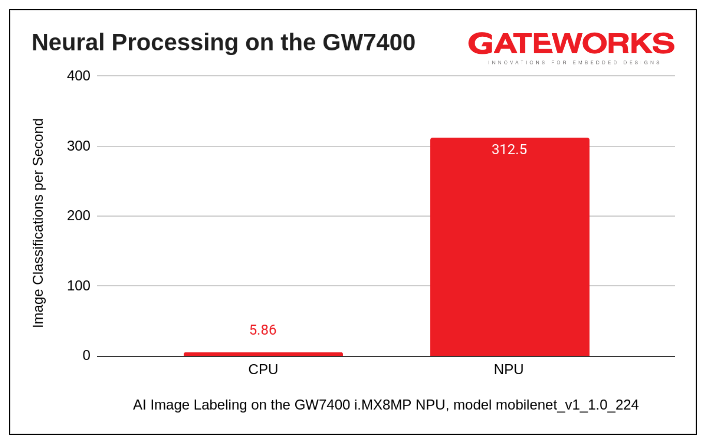
Without the NPU: Image Classification time: 170.5 ms
With the NPU: Image Classification: 3.2 ms
Without considering the warmup times, this is a >98% speedup! For every CPU frame, the NPU can process 53.
This data is derived from classifications/sec = 1/(image classification time)
GStreamer Example for Detection
Section 8.2 of the Machine Learning Users Guide details this process, such as how to download the necessary models. After following the download steps, the home/root/nxp-nnstreamer-examples/ directory on your board should have a downloads directory with models and media directories. If not, you need to run the update script on your host to compile the models and scp them to the board.
On your host, execute the following command to have GStreamer take in video over UDP.
gst-launch-1.0 udpsrc port=5000 ! application/x-rtp,payload=96 ! rtpjpegdepay ! jpegdec ! autovideosink

Host GStreamer pipeline (SVG)
On your board, execute the following to send a stream over UDP to the host port 5000. This script was derived from Section 8.1 of the Machine Learning Users Guide. The GStreamer command takes in a video input and overlays both bounding boxes and labels on it using TensorFlow and NXP filters.
CAMERA= <your camera device, such as /dev/video2> HOST_IP= <desktop ip addr> gst-launch-1.0 v4l2src name=cam_src device=${CAMERA} num-buffers=-1 ! video/x-raw,width=640,height=480,framerate=30/1 ! tee name=t t. ! queue name=thread-nn max-size-buffers=2 leaky=2 ! imxvideoconvert_g2d ! video/x-raw,width=300,height=300,format=RGBA ! videoconvert ! video/x-raw,format=RGB ! tensor_converter ! tensor_filter framework=tensorflow-lite model=/home/root/nxp-nnstreamer-examples/detection/../downloads/models/detection/ssdlite_mobilenet_v2_coco_quant_uint8_float32_no_postprocess.tflite custom=Delegate:External,ExtDelegateLib:libvx_delegate.so ! tensor_decoder mode=bounding_boxes option1=mobilenet-ssd option2=/home/root/nxp-nnstreamer-examples/detection/../downloads/models/detection/coco_labels_list.txt option3=/home/root/nxp-nnstreamer-examples/detection/../downloads/models/detection/box_priors.txt option4=640:480 option5=300:300 ! videoconvert ! queue ! mix. t. ! queue name=thread-img max-size-buffers=2 leaky=2 ! videoconvert ! mix. imxcompositor_g2d name=mix latency=30000000 min-upstream-latency=30000000 sink_0::zorder=2 sink_1::zorder=1 ! videoconvert ! jpegenc ! rtpjpegpay ! udpsink host=${HOST_IP} port=5000

GW74xx AI-detection GStreamer pipeline (SVG)
If everything works properly, you should instantly see your video input streamed to your desktop host. After a few seconds of warming up, the bounding boxes from the TensorFlow Detection filter will be overlaid on the video. The stream properties can be changed for different resolutions and framerates; see gstreamer/streaming. NOTE: This example is object detection, which differs from the image classification that we got benchmark data from in the previous section.

References
Attachments (10)
- 0001-arm64-dts-imx8mp-venice-fix-USB_OC-pinmux.patch (2.7 KB ) - added by 2 years ago.
- 0002-arm64-dts-imx8mm-venice-gw700x-remove-ddrc.patch (963 bytes ) - added by 2 years ago.
- 0003-arm64-dts-freescale-add-Gateworks-venice-board-dtbs.patch (1.4 KB ) - added by 2 years ago.
- 0004-arm64-dts-imx8mp-venice-gw74xx-enable-gpu-nodes.patch (1.1 KB ) - added by 2 years ago.
- imx8mp_border.png (387.1 KB ) - added by 2 years ago.
-
Screenshot from 2024-08-09 12-16-33.png
(33.0 KB
) - added by 2 years ago.
updated benchmark data
- gw74xx_npu_benchmark_new.png (39.1 KB ) - added by 2 years ago.
- pipeline.svg (84.9 KB ) - added by 2 years ago.
- hostpipeline.svg (20.3 KB ) - added by 2 years ago.
- hostpipeline.2.svg (20.3 KB ) - added by 2 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip